23億枚もの画像で構成された画像生成AI「Stable Diffusion」のデータセットのうち1200万枚がどこから入手した画像かを調査した結果が公開される

画像生成AI「Stable Diffusion」は入力したキーワードに沿って画像を出力してくれるAIで、簡単なお絵かきとキーワードを合わせて意図した画像を生成したり、「この画像っぽい○○」といった指示でイメージを形にできたりと、さまざまな機能や手法が生み出されています。そんなStable Diffusionについて、「画像を学習するAIは、ウェブ上のどのような画像を学習しているのか?」という疑問を解明するために、23億枚のデータセットから1200万枚を抜粋して集計した調査結果を、技術者・ブロガーのアンディ・バイオ氏が公開しています。
Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion's Image Generator - Waxy.org
https://waxy.org/2022/08/exploring-12-million-of-the-images-used-to-train-stable-diffusions-image-generator/
Simon Willison’s Weblog
https://simonwillison.net/
Kickstarterの元最高技術責任者(CTO)で、主にインターネット文化や知的財産権の問題、アートとテクノロジーについて執筆するブログ「Waxy.org」を運営するバイオ氏は、2022年8月30日にStable Diffusionの画像学習データについての調査結果を公開しました。バイオ氏によると、Stable Diffusionは他の画像生成や分析を行うAIに比べて、モデルのトレーニング方法に透明性があるとのこと。しかし、実際に画像のトレーニングを行っているデータセットを特定することは難しく、バイオ氏は友人であり技術者のサイモン・ウィリソン氏と協力し、Stable Diffusionのトレーニングに用いられた23億枚の画像のわずか0.5%となる約1200万枚の画像データを取得しました。
収集されたデータセットは以下のサイトで見ることができます。
laion-aesthetic-6pls: images: 12,096,835 rows
https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/images
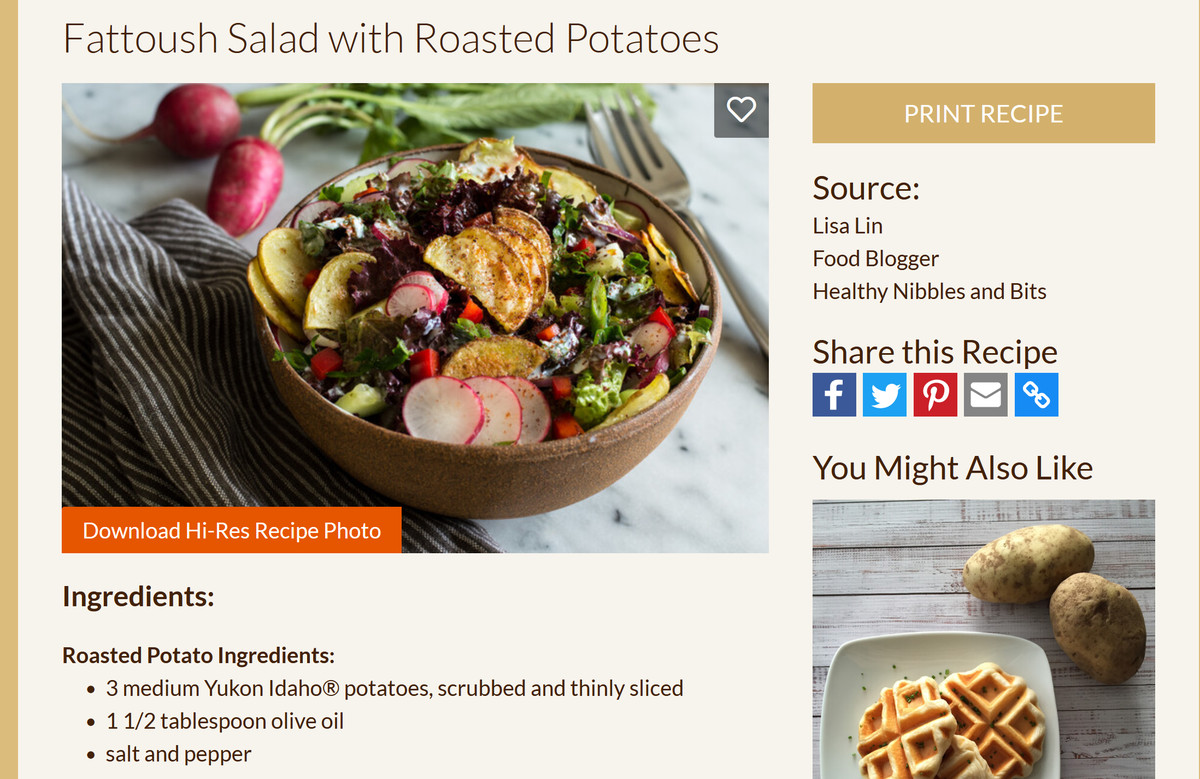
データセットを一覧にしたサイトでは、画像に付随するテキストやサイズなどの情報のほか、画像を収集したサイトのドメインも記載されていました。試しにサラダの画像の参照元となるURLを訪問してみます。
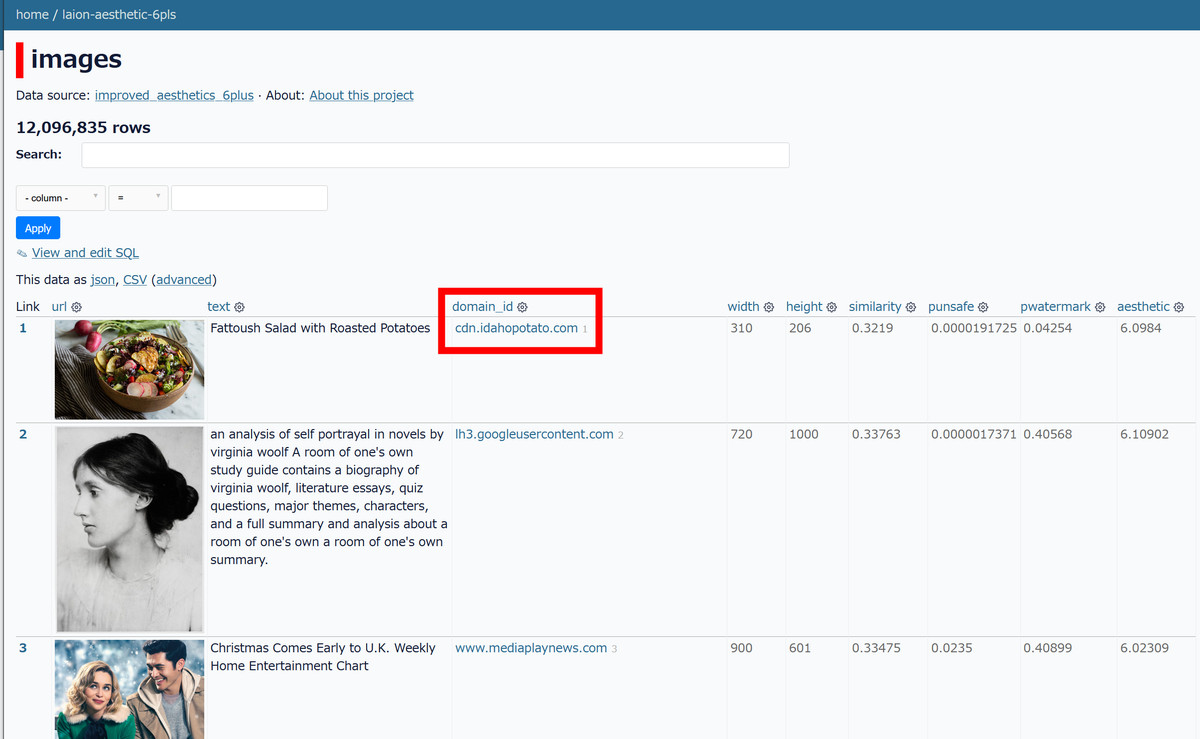
すると、「アイダホポテト」というじゃがいものポータルサイトに遷移しました。ここでは、アイダホポテトについての情報や、じゃがいもの調理・保存方法などのアイデアのほか、アイダホポテトを用いたレシピなども公開されています。
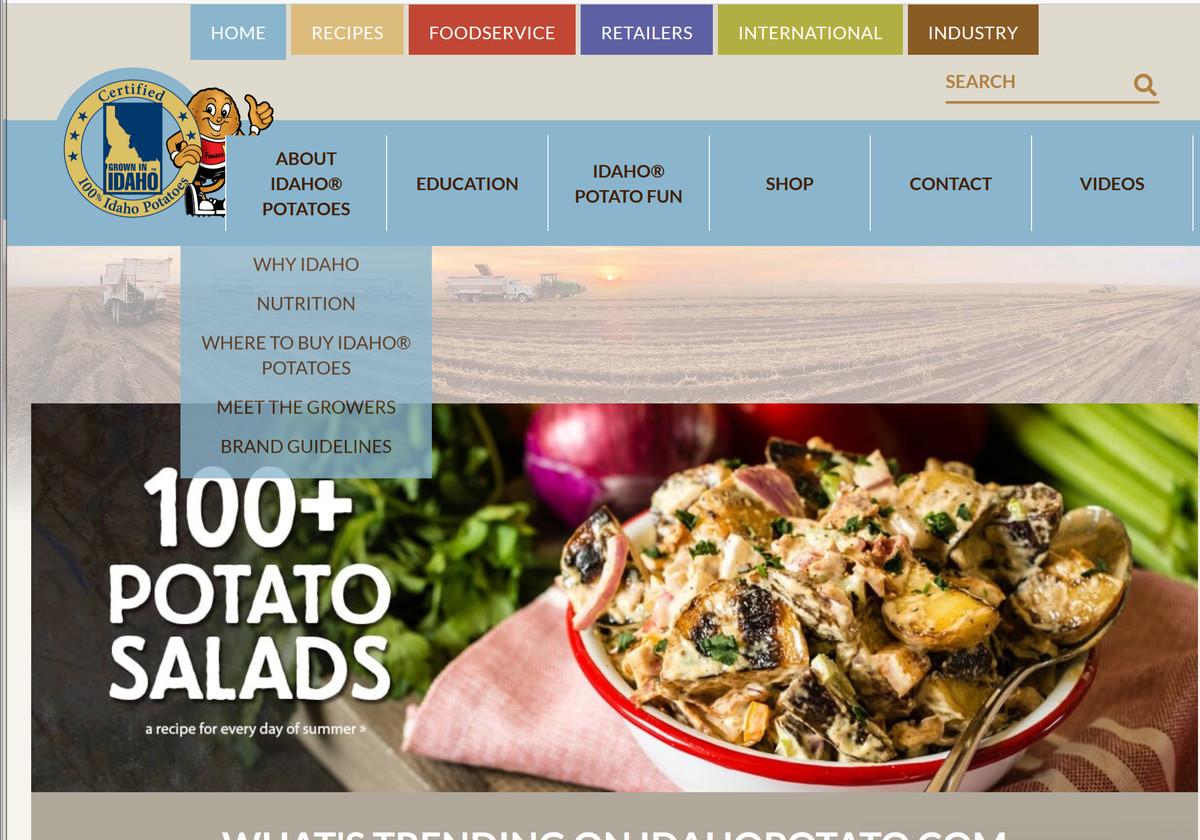
レシピを検索したところ、データセット一覧にあった画像と同じ「ローストポテトのファットゥーシュサラダ」の写真を発見。このように、「ここの画像がAIの学習および画像を自動生成するのに使われているのか」と分かります。
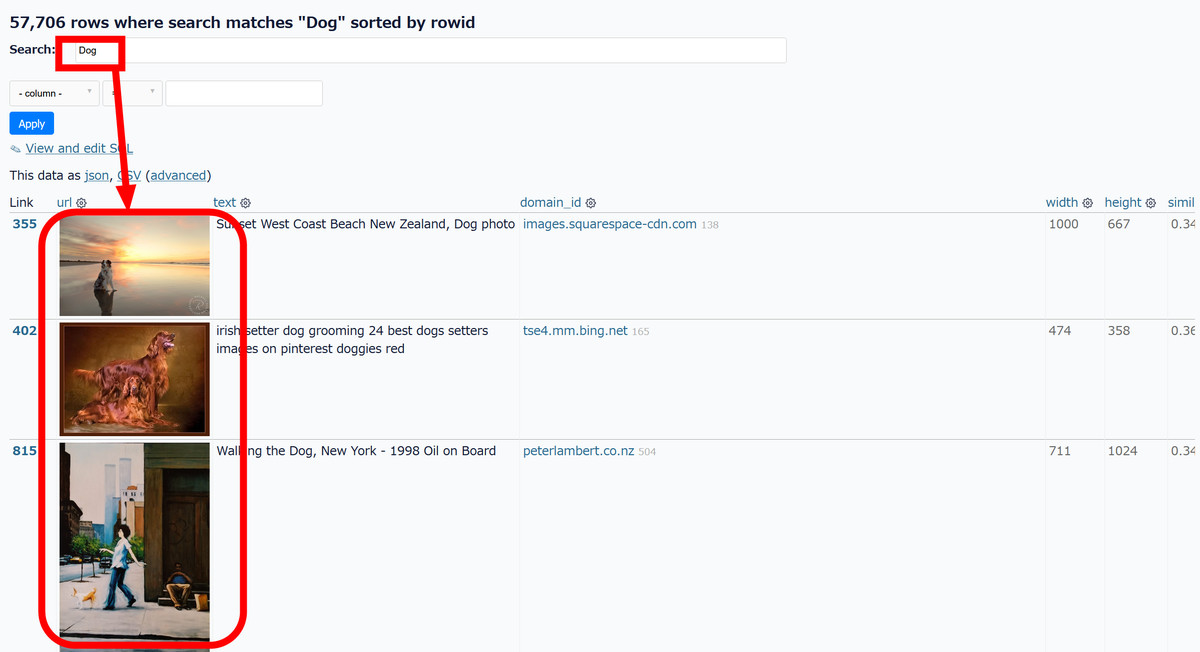
また、データセット一覧では画像をキーワード検索することも可能です。試しに「Search」に「Dog」と入力してみると、さまざまなイヌの画像が表示されました。
バイオ氏によると、Stable DiffusionはオープンなAIネットワークを無料で公開する非営利団体のLAIONによって収集された、3つの大規模なデータセットからトレーニングされています。LAIONの画像データセットは、毎月数十億のウェブページからデータを抽出して大規模なデータセットとしてリリースする非営利団体であるCommon Crawlから構築されています。Stable Diffusionのトレーニングでは、LAIONのデータセットから「解像度が十分に高い」「『美的スコア』が『5』以上ある」「透かしが入っていない」などの条件で画像データを絞り込み、サンプルを構築しています。
バイオ氏は取得したStable Diffusionのデータサンプルに「どのサイトから抽出されたデータか」をドメインごとに区別しタグ付けを行いました。バイオ氏によると、100種類のドメインから抽出された画像が約47%を占めており、特にPinterestからは全データセットの8.5%が抽出されていると分かったそうです。また、WordPressを用いたブログ内の画像が6.8%あったほか、FlickrやDeviantArt、Tumblrなどの画像共有サイトではそれぞれ数万から数十万枚の画像が収集されており、「ユーザー生成型のコンテンツプラットフォームは、画像データの巨大なソースでした」とバイオ氏は語っています。
また、ショッピングサイトからの画像もデータセットの中で大きな割合を占めています。アートプリントとポスターを販売するFine Art Americaは全体で2番目に多い5.8%となる約70万枚が含まれていたほか、カナダのeコマースサイトであるShopifyが約24万枚、ウェブサイト作成ツールのWixおよびSquarespaceのショップぺージからそれぞれ約19万枚と、かなりの量がデータセットに含まれていたそうです。
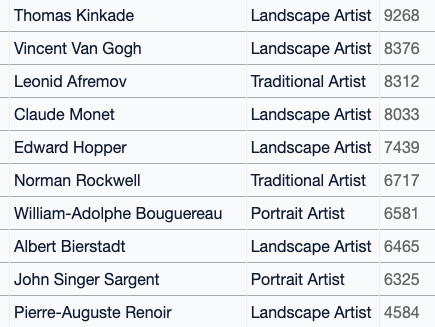
収集したデータセットはアーティスト別に見ることもできます。バイオ氏は「(Googleドキュメント)隠されたアーティストの百科事典」を用いて1800人以上のアーティスト名を検索し、アーティストの名前を参照する画像を集計しました。結果として、データセットのうちもっとも多く名前の検索でヒットしたアーティストは、「光の画家」と自らを表現するトーマス・キンケード氏で、9268枚の画像が含まれていました。また、データセットのアーティストはカテゴリ別に検索することも可能で、「コミック」カテゴリに絞って検索すると、マーベル・コミックのスタン・リー氏が最も頻繁に見られたそうです。
同様に、有名人の名前をリストアップして集計したところ、最も引用されている名前はドナルド・トランプ前大統領で約1万1000枚、次点が女優のシャーリーズ・セロン氏で9576枚となっていたとのこと。

最後に、架空のキャラクターについての集計結果もバイオ氏は公開しています。ここで数が多かったのはキャプテンマーベル(4993枚)やブラックパンサー(4395枚)、キャプテンアメリカ(3155枚)とマーベル作品が並んでいます。続いてバットマン(2950枚)とスーパーマン(2739枚)が僅差で並び、「スターウォーズ」のルーク・スカイウォーカー(2240枚)はダース・ベイダー(1717枚)やハン・ソロ(1013枚)よりも多くの画像が確認された様子。また、ミッキーマウスは520枚の画像が収集されており、データセット内のキャラクターの中でギリギリトップ100にランクインしていました。アーティストや有名人、キャラクターについての集計はいずれも、全23億枚のデータセットのうち0.5%を集計したものであり、一覧を検索してヒットしないからといってデータセット内にないわけではないことに注意が必要です。
バイオ氏に協力したウィリソン氏は自身のブログで、「トレーニングに用いられた画像がブラックボックスではなくなることで、AIの倫理問題が難しくなると思います」と語っています。ウィリソン氏によると、トレーニングセット内の各画像が自動生成される画像に対して提供する部分はごくわずかであり、ネットワーク全体に広がる数値の比重を微調整するにすぎません。しかし、データセットとして抽出された元の画像を作成した人は、AIを自身の生活に対する直接的な脅威とみなすことがあるとのこと。ウィリソン氏はそのような感覚の人を「AIヴィーガン」と表現し、ヴィーガンの人を尊重しつつも自身は肉を摂取するように、画像生成AIの価値観を受け入れられない人を尊重しつつも、画像生成AIの素晴らしい可能性を試していきたいという姿勢を示しています。
・関連記事
キーワードに沿ってまるで人間が描いたような絵や写真を生み出すAI「Stable Diffusion」が一般公開されたので使ってみた - GIGAZINE
簡単なお絵かきとキーワードだけで思い通りの写真やイラストを自動生成する「img2img」モードを「Stable Diffusion」で誰でも試してみることができるサイト - GIGAZINE
「この画像っぽい○○を生成」を画像生成AI「Stable Diffusion」で実現する技術が登場 - GIGAZINE
まるで人間のアーティストが描いたような画像を生成するAIが「アーティストの権利を侵害している」と批判される - GIGAZINE
Intel製CPUでも画像生成AI「Stable Diffusion」を動かせる「stable_diffusion.openvino」が登場、誰でもダウンロード可能に - GIGAZINE
・関連コンテンツ