







テキストを入力するだけで3Dモデルを生成できる3D自動生成AI「DreamFusion」

入力したテキストをベースに画像を出力する「Stable Diffusion」のような拡散モデルが流行していますが、このアプローチを進化させて「テキストから3Dモデルの生成」を実現する3D自動生成AI(人工知能)「DreamFusion」の開発にGoogle Researchやカリフォルニア大学バークレー校の研究者たちが取り組んでいます。
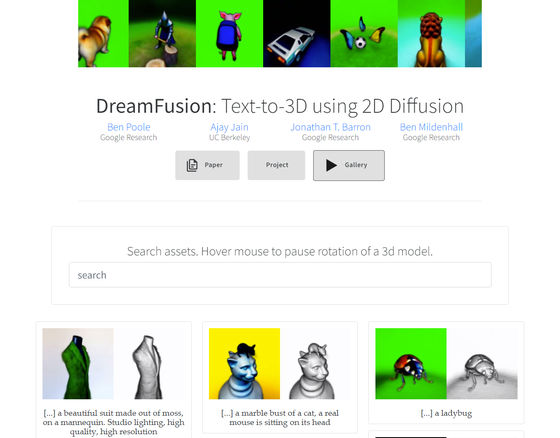
DreamFusion: Text-to-3D using 2D Diffusion
https://dreamfusion3d.github.io/
通常、「テキストから3Dモデルを自動生成できるAI」を構築するには、「ラベル付けされた3Dアセットからなる大規模データセット」と「3Dデータのノイズを除去するための効率的なアーキテクチャ」の2つが必要となります。しかし、DreamFusionにはそのどちらも存在しません。DreamFusionでは、事前トレーニング済みのテキストから2D画像を出力できる拡散モデルと、Googleのエンジニアが開発したディープドリームを用いることで、さまざまな角度から2D画像を出力。これをベースに3Dモデルを生成します。
これは複数の静止画から3Dモデルを生成する「NeRF」によく似たテクノロジーを利用しているとのこと。NeRFを使うとどのような3Dモデルを生成できるのかは、以下の記事を読めばよくわかります。
複数の静止画から3Dモデルを生成する技術「NeRF」はディープフェイクを進歩させるのか? - GIGAZINE

より具体的に説明すると、DreamFusionはImagenと呼ばれる「テキストから画像を生成する拡散モデル」を用いて3Dモデルを作成します。DreamFusionでは損失関数を最適化することで、拡散モデルからサンプルを生成するという新しい手法の「Score Distillation Sampling(SDS)」を採用しており、これにより3D空間などの任意のパラメーター空間でサンプルを最適化することが可能となります。SDSだけでも適切な3Dモデルを生成することができるそうですが、これに正則化や最適化戦略を追加することでジオメトリを改善することで、より一貫性のあるNeRFモデルを生成可能となるそうです。
実際にDreamFusionの公式ページにアクセスし、ページ中段にある「Generate 3D from text yourself!」(あなたの入力したテキストから3Dを生成しよう!)と書かれたエリアで、入力したテキストにより出力される3Dモデルがどのように変化するのかを確認できます。

選択可能なオプションは以下の通り。
・上段
「a DSLR photo of a squirrelan」(デジタル一眼レフカメラで撮影したリスの写真)
「intricate wooden carving of a squirrela」(複雑な木彫りのリス)
「highly detailed metal sculpture of a squirrel」(非常に詳細な金属の彫刻)
・中段
「wearing a kimono」(着物を着用)
「wearing a medieval suit of armor」(中世の甲冑を着用)
「wearing a purple hoodiewearing an elegant ballgown」(上品な夜会用の服を着用)
・下段
「reading a book」(本を読む)
「riding a motorcycle」(バイクに乗る)
「playing the saxophone」(サックスを吹く)
「chopping vegetables」(野菜を刻む)
「sitting at a pottery wheel shaping a clay bowl」(ろくろの前に座り器を作成)
「riding a skateboard」(スケートボードに乗る)
「wielding a katana」(刀を振り回す)
「eating a hamburger」(ハンバーガーを食べる)
「dancing」(踊る)
以下は「a DSLR photo of a squirrelan」「wearing a medieval suit of armor」「sitting at a pottery wheel shaping a clay bowl」を選択した際に出力される3Dモデル。

さらに、DreamFusionを用いて生成された3Dモデルの事例が以下のページにまとめられています。
DreamFusion: Text-to-3D using 2D Diffusion
https://dreamfusion3d.github.io/gallery.html
・関連記事
キーワードに沿ってまるで人間が描いたような絵や写真を生み出すAI「Stable Diffusion」が一般公開されたので使ってみた - GIGAZINE
画像生成AI「Stable Diffusion」の実行環境を無料でWindows上に構築できる「Stable Diffusion web UI」の導入方法まとめ - GIGAZINE
画像生成AI「Stable Diffusion」を使いこなすために知っておくと理解が進む「どうやって絵を描いているのか」をわかりやすく図解 - GIGAZINE
画像生成AI「Stable Diffusion」が実はかなり優秀な画像圧縮を実現できることが判明 - GIGAZINE
画像生成AI「Stable Diffusion」でどれぐらいプロンプト・呪文の指示に従うかを決める「CFG(classifier-free guidance)」とは一体何なのか? - GIGAZINE
画像生成AI「Stable Diffusion」がTensorFlowとKerasCVで約30%高速になることが判明 - GIGAZINE
・関連コンテンツ







