







Databricksがオープンな大規模言語モデル「DBRX」をリリース、GPT-3.5やCodeLLaMA-70Bを上回る性能

データ分析ツールなどを提供する企業のDatabricksが、2024年3月27日にオープンな汎用大規模言語モデル(LLM)である「DBRX」を発表しました。オープンライセンスでの配布となっており、月間アクティブユーザーが7億人以下の企業は無料で商用利用が可能となっています。
Introducing DBRX: A New State-of-the-Art Open LLM | Databricks
https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm

DBRXはトランスフォーマーのデコーダーを使用するLLMで、「mixture-of-experts(MoE)」アーキテクチャが採用されています。パラメータの合計数は1320億となっていますが、全ての入力に反応するのは360億パラメータのみで、残りのパラメータは「専門家」として必要に応じてアクティベートされます。MoEアーキテクチャを採用することで、サイズを抑えて高効率の学習や推論を可能にしつつ性能を高めたとのこと。
同じくMoEアーキテクチャを採用したMixtralやGrok-1が8人の専門家を搭載し、入力ごとに2人をアクティベートするのに対し、DBRXは16人の専門家を搭載して入力ごとに4人をアクティベートします。専門家の組み合わせ数が65倍になったことでモデルの品質が向上したと述べられています。
また、DBRXは最大コンテクスト長3万2000トークンの合計12兆トークンのデータでトレーニングされました。「専門家」が混在するMoEモデルをトレーニングするのは難しかったものの、効率的な方法で繰り返しトレーニングできる堅牢なパイプラインを開発し、誰でもDBRXレベルのMoE基礎モデルをゼロからトレーニングできるようにしたと述べられています。
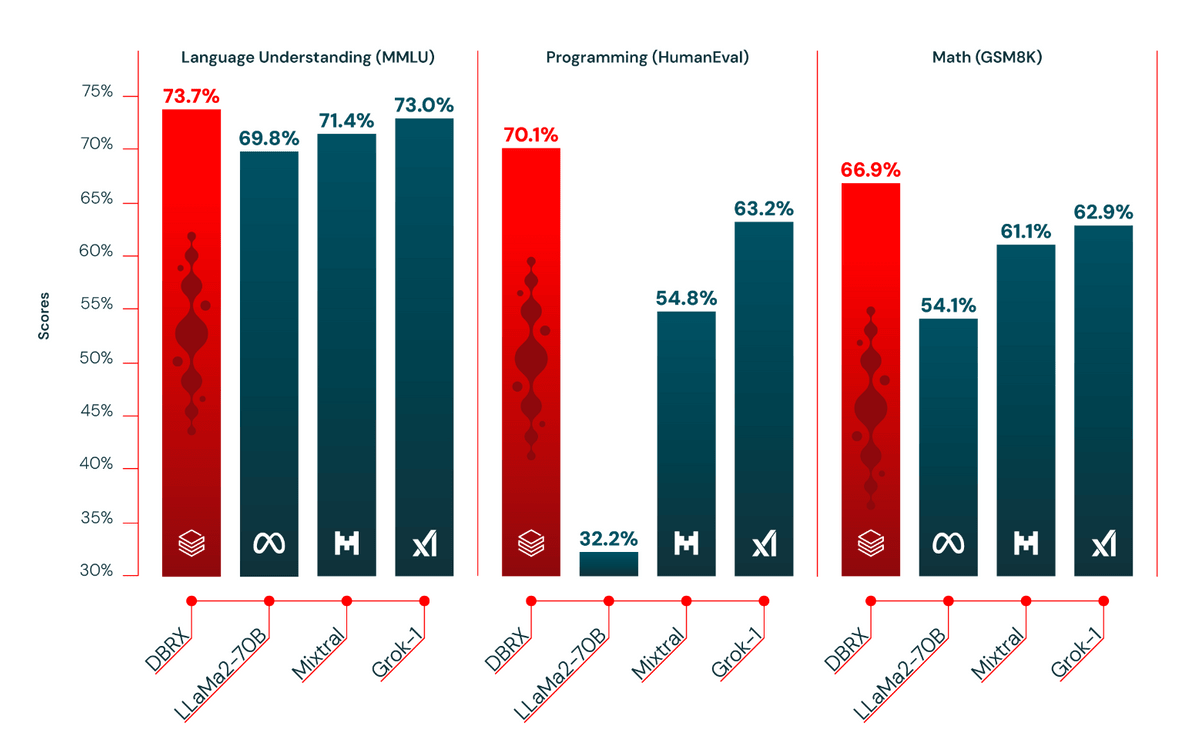
下図は「言語理解」「プログラミング」「数学」のベンチマーク結果で、DBRXはLLaMa2-70BやMixtral、Grok-1などのモデルよりも良い結果を出していることが分かります。また、専門家を搭載することで汎用性能を確保しながらプログラミングなど特化が必要な領域における性能も確保できています。
また、「GPT-3.5」「GPT-4」「Claude 3シリーズ」「Gemini 1.0 Pro」「Gemini 1.5 Pro」「Mistral」といったクローズドソースのLLMとの比較結果は下図の通り。ざっくり見るとDBRX InstructはGemini 1.0 ProやMistral Mediumなどと同等のレベルに見えます。
Model | DBRX | |||||||||
MT Bench (Inflection corrected, n=5) | 8.39 ± 0.08 | — | — | 8.41 ± 0.04 | 8.54 ± 0.09 | 9.03 ± 0.06 | 8.23 ± 0.08 | — | 8.05 ± 0.12 | 8.90 ± 0.06 |
MMLU 5-shot | 73.7% | 70.0% | 86.4% | 75.2% | 79.0% | 86.8% | 71.8% | 81.9% | 75.3% | 81.2% |
HellaSwag 10-shot | 89.0% | 85.5% | 95.3% | 85.9% | 89.0% | 95.4% | 84.7% | 92.5% | 88.0% | 89.2% |
HumanEval 0-Shot | 70.1% temp=0, N=1 | 48.1% | 67.0% | 75.9% | 73.0% | 84.9% | 67.7% | 71.9% | 38.4% | 45.1% |
GSM8k CoT maj@1 | 72.8% (5-shot) | 57.1% (5-shot) | 92.0% (5-shot) | 88.9% | 92.3% | 95.0% | 86.5% (maj1@32) | 91.7% (11-shot) | 81.0% (5-shot) | |
WinoGrande 5-shot | 81.8% | 81.6% | 87.5% | — | — | — | — | — | 88.0% | 86.7% |
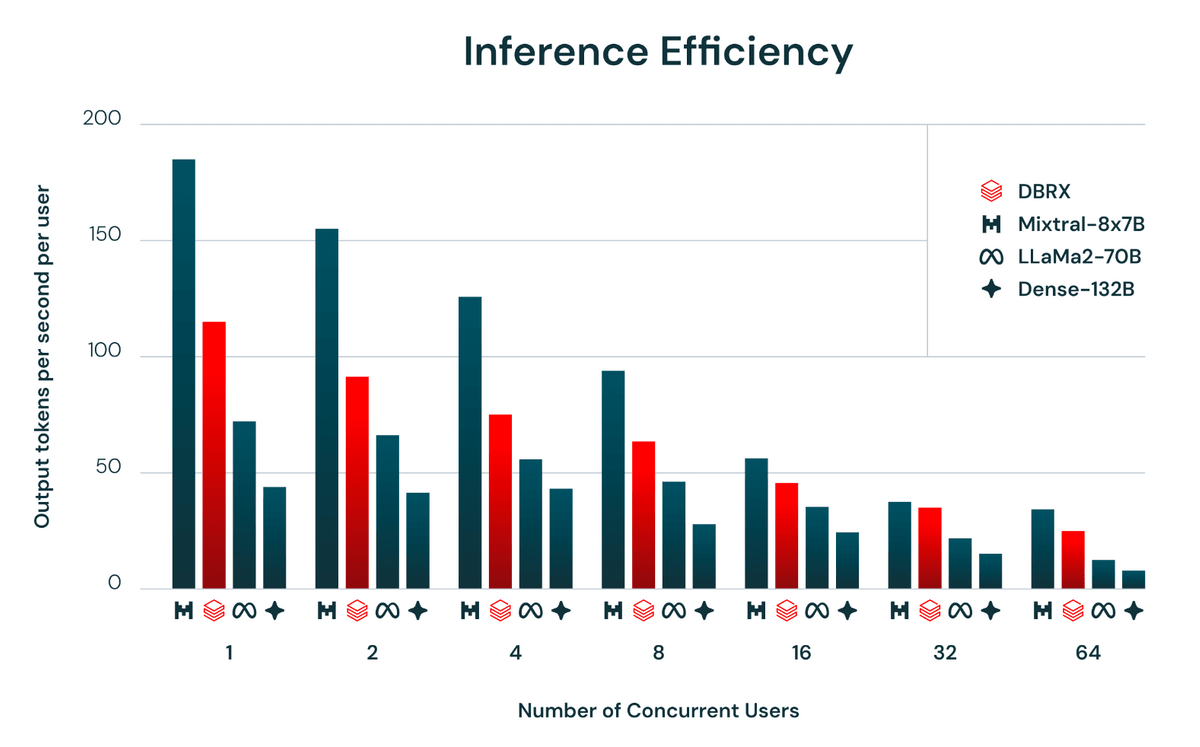
推論の効率を示す「1秒・1ユーザーあたりの出力トークン数」は下図の通り。いずれのユーザー数においても、より小さいモデルであるMixtral-8x7Bが最大の出力を誇っています。一方、赤線で示されているDBRXの推論効率はLLaMa2-70BやDense-132Bを大きく上回りました。
基礎モデルとなる「DBRX Base」と、ファインチューニング済みのモデル「DBRX Instruct」はともにHugging Faceにてオープンライセンスで配布されているほか、DatabricksのFoundation Model API経由で簡単に利用可能とのことです。
・関連記事
大規模言語モデルの動作をExcelで完全に再現することでプログラミングをせずにAIの構造を学習できるシートが登場 - GIGAZINE
無料で商用利用可能な大規模言語モデル「Mixtral 8x7B」が登場、低い推論コストでGPT-3.5と同等以上の性能を発揮可能 - GIGAZINE
Googleがオープンかつ商用利用可能で軽量な大規模言語モデル「Gemma」を公開 - GIGAZINE
101言語に対応したオープンソースの大規模言語モデル「Aya」をCohere for AIがリリース - GIGAZINE
ネット上に流出した大規模言語モデルは自社製のものだとAI企業・MistralのCEOが確認 - GIGAZINE
・関連コンテンツ







